Speaker: Andrei Ivanov
Existing Transformer implementations attain much less than peak GPU flops
On BERT-large they demonstrate performance improvement:
- 30% over PyTorch
- 20% over Tensorflow + XLA
- 8% over DeepSpeed
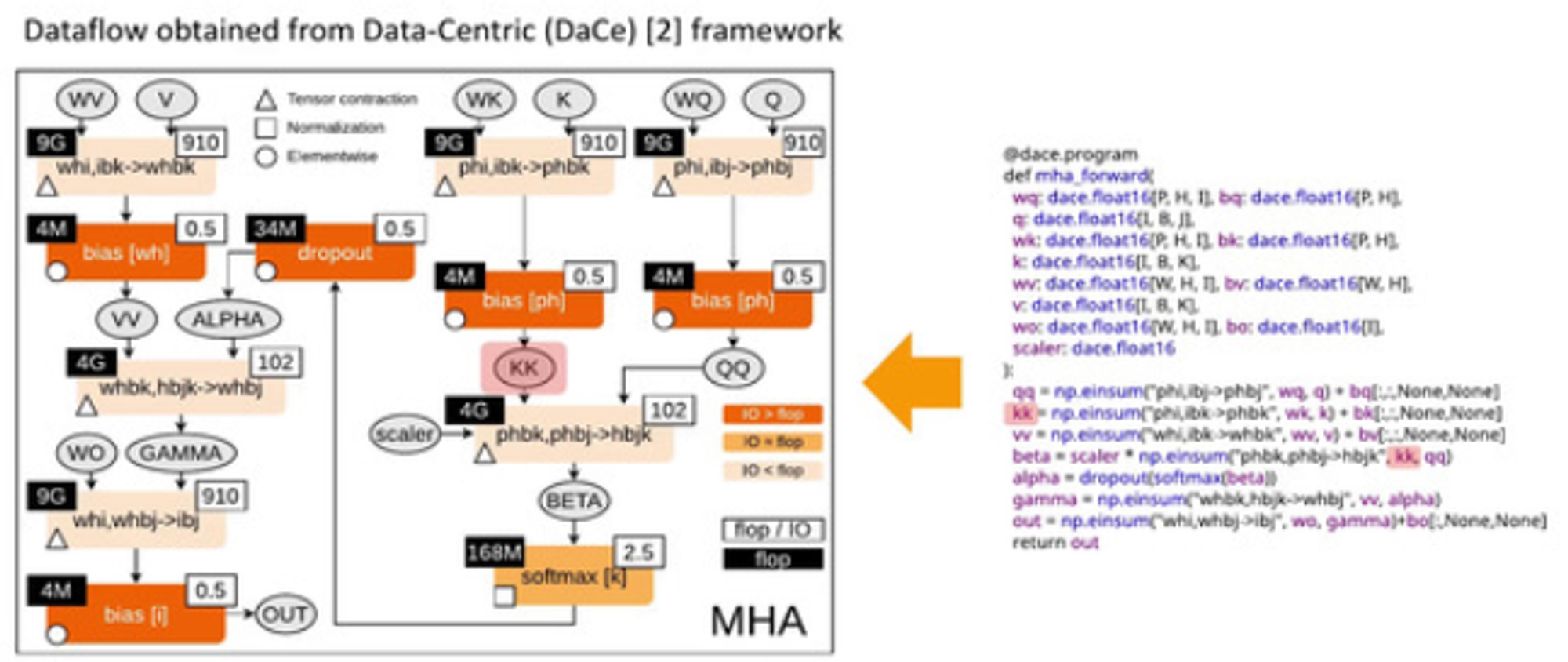
Data movement is the bottleneck
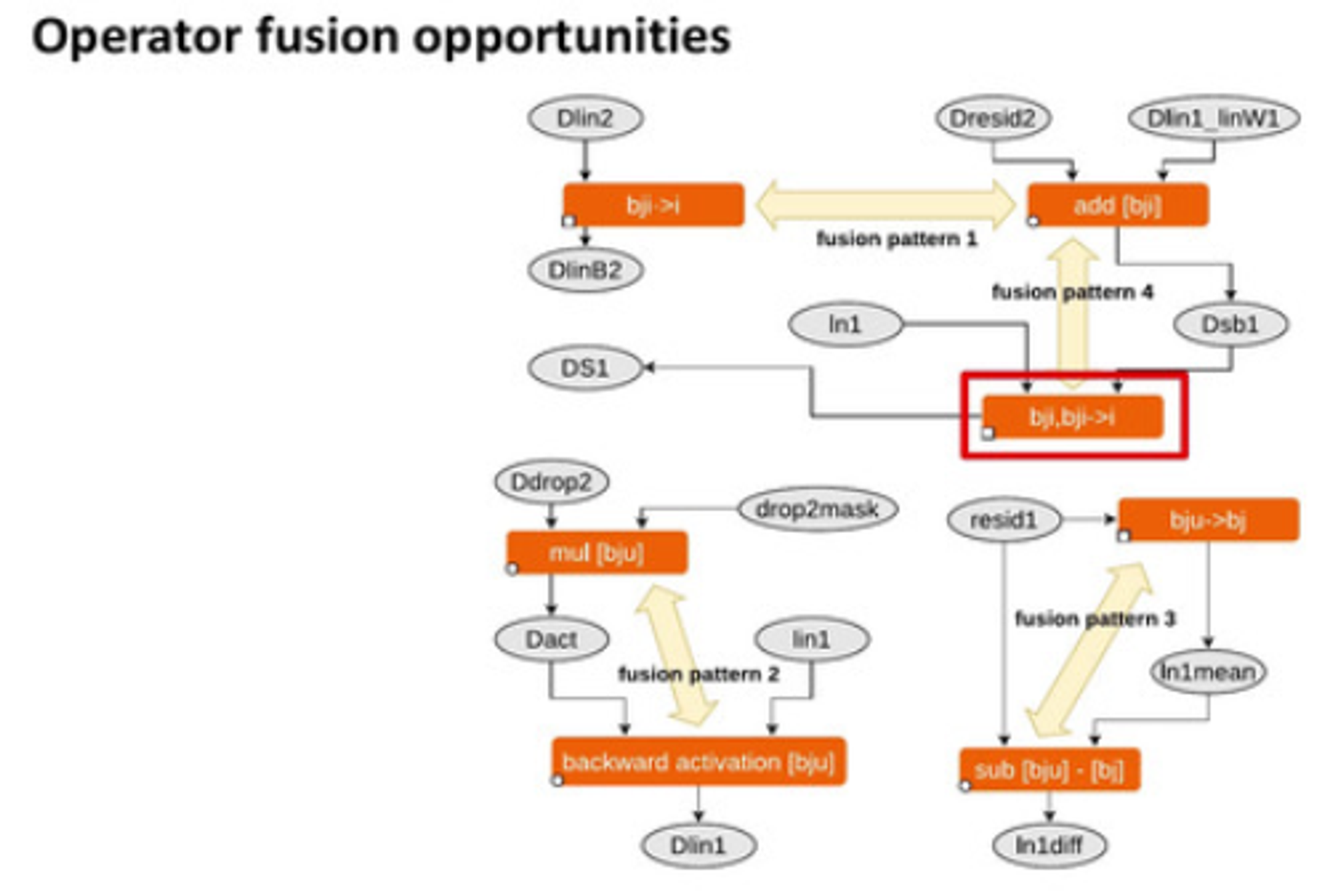
Group operators into 3 classes:
Tensor contractions = matmuls
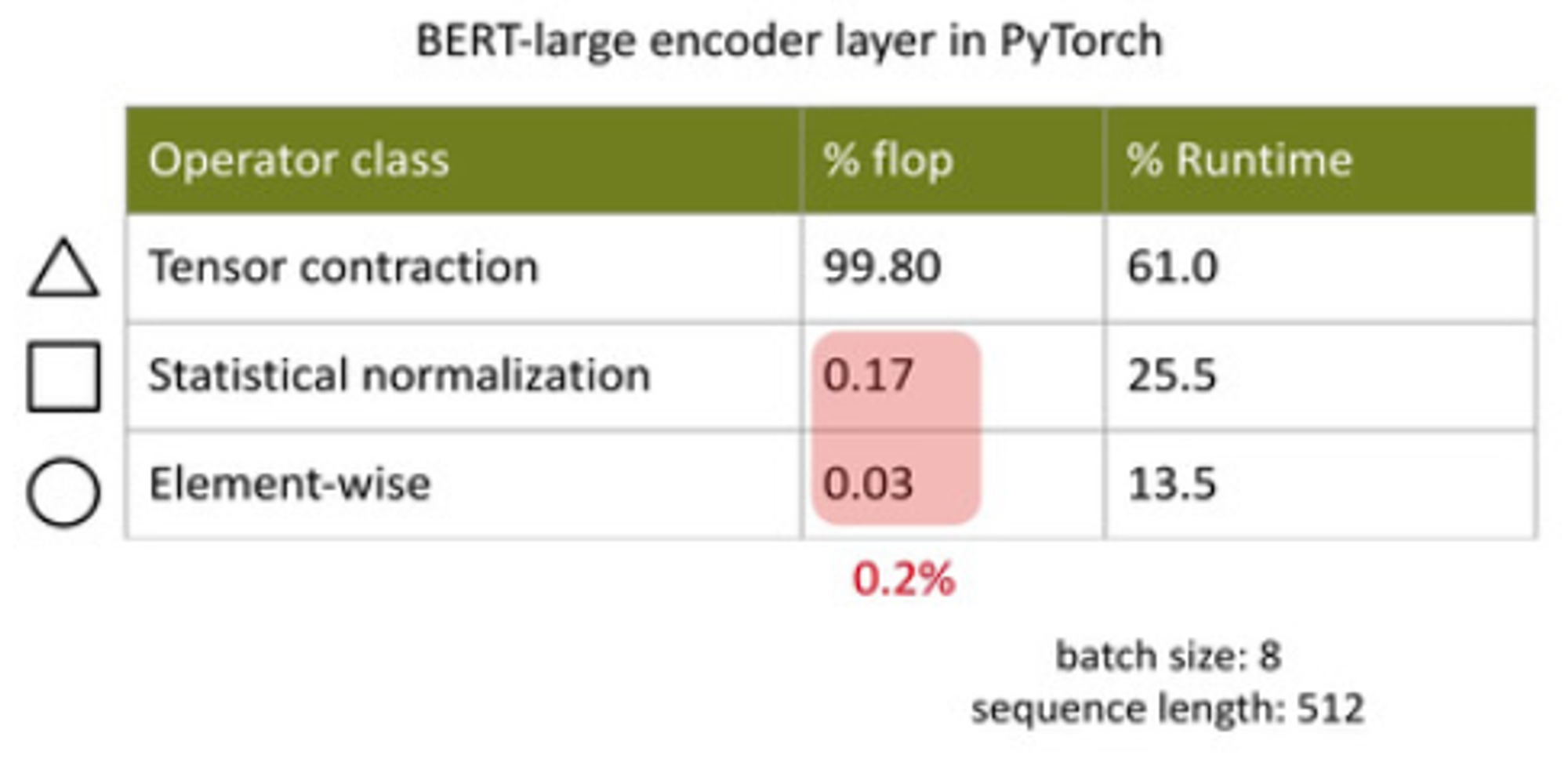
Norm = softmax / layernorm
encoder, biases, "repulse/repose activations", residual connections
Dataflow graph: multi-head attention
Operator fusion opportunities