Speaker: Nicholas Lane (Cambridge)
Huge progress made over recent years in model efficiency/compression - but GNNs virtually absent from this discussion!
Improved performance in this area critical to future success of GNNs.
Key domains where GNN improvements will yield benefits:
- Recommender systems
- Chip design
- Simulating physics/chemistry
- Drug discovery
- Scene generation
Great progess has been made in creating new GNN models that can solve various problems; but we lag behind badly in efficiency.
ML Efficiency is hard, for GNNs even harder - why?
- Gnns lack regularity we see in, say, CNNs - e.g. no ordering or fixed neighbourhood
- This regularity is often the root of optimisation
GNN overheads depend on type of input data

Observe that these different datasets require massively different amounts of compute.
For most non-GNN architectures, it is not the case that overheads are closely tied to type of data - CNNs shown on dotted lines.
Degree-Quant
What is quantisation?
Use fewer bits tot represent params - particularly for performing inference.
Benefits: smaller models, less data movement, lower latency
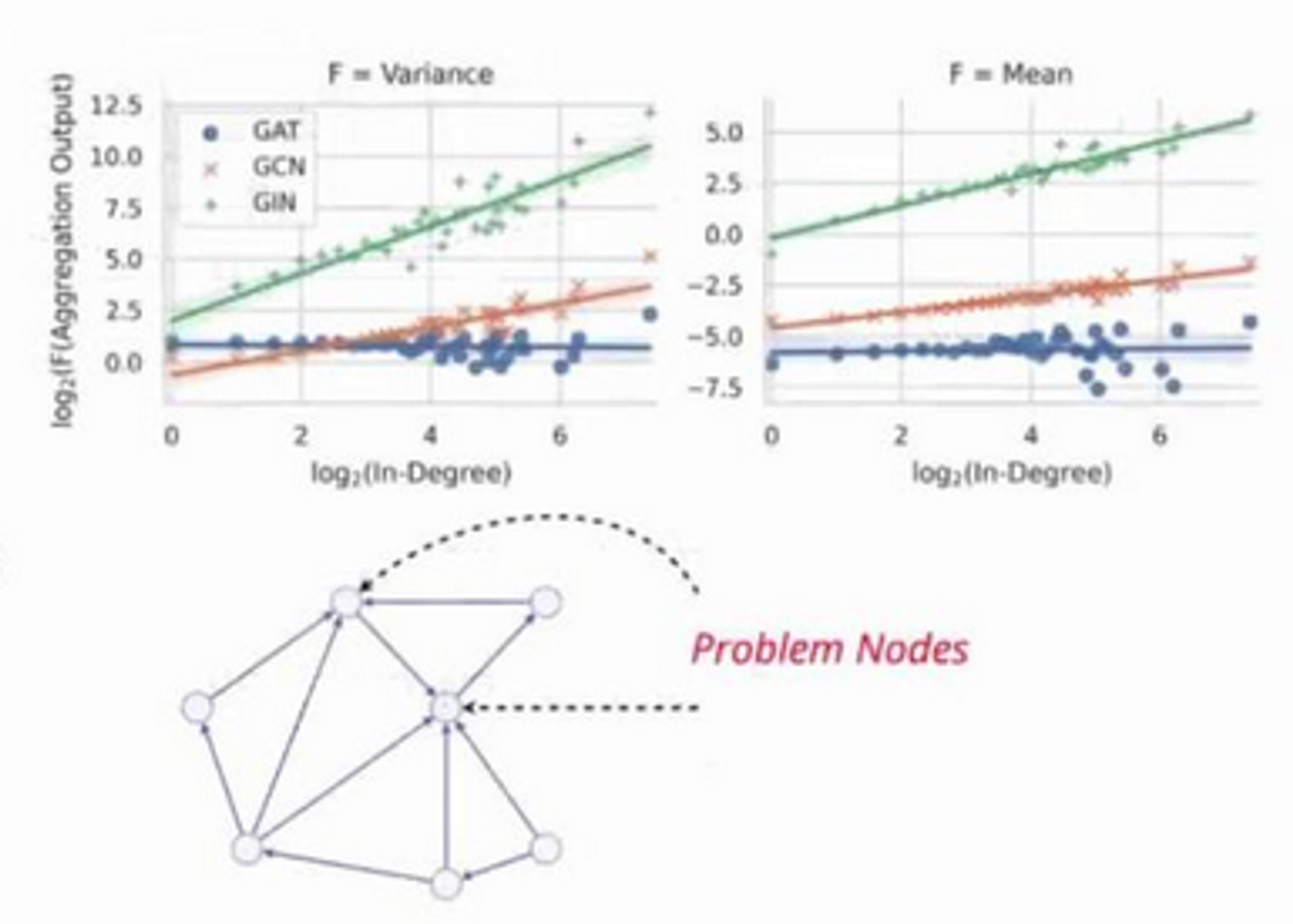
GNN-specific quantisation challenges
- Large variance in tensor values after aggregation
- High (in-)degree nodes disproportionately affect gradient error
Method
Build on top of existing stochastic quantisation-aware training.
- Introduce two important ideas. Due to recognition of some nodes being highly sensitive, we want to stochastically protect nodes based on:
- Stochastic masking that is applied to all nodes - protect these nodes by performing forward-pass at full precision
- Based on where they sit in the topology
- Build a scheme to carefully set the boundaries of quantisation
In CNNs where you set these boundaries doesn't make much of a difference - it turns out the same it not true for graphs!
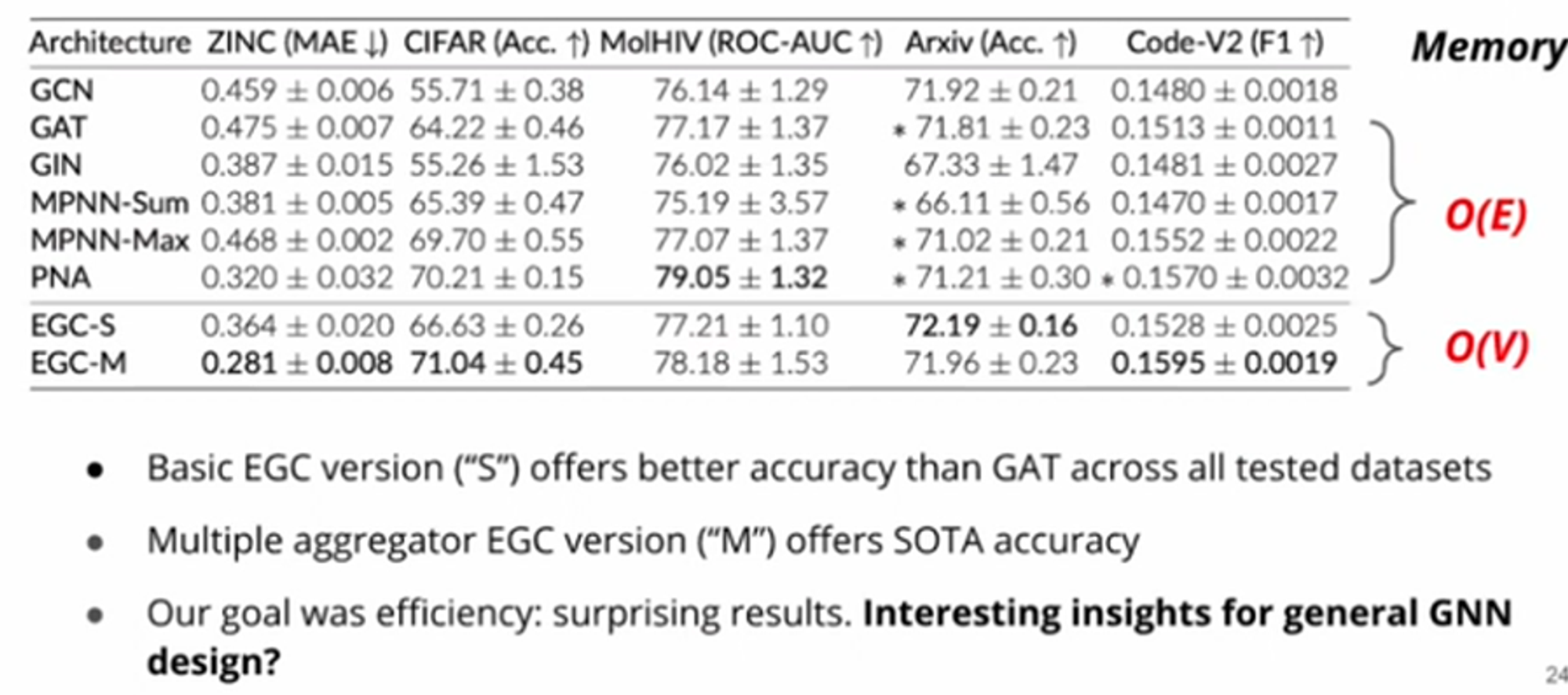
Results
By applying this quantisation scheme for int8 gives competetive levels of accuracy as FP32.
Means that serving production GNN models can be done much faster with minimal accuracy loss!
Measured speedup of up to 4.7x on CPU (INT8)
Efficient Graph Convolutions
Key contributions:
- Less memory than alternatives: vs.
- Lower latency than alternatives
- Higher accuracy
(wow!)
Where have GNN improvements originated?
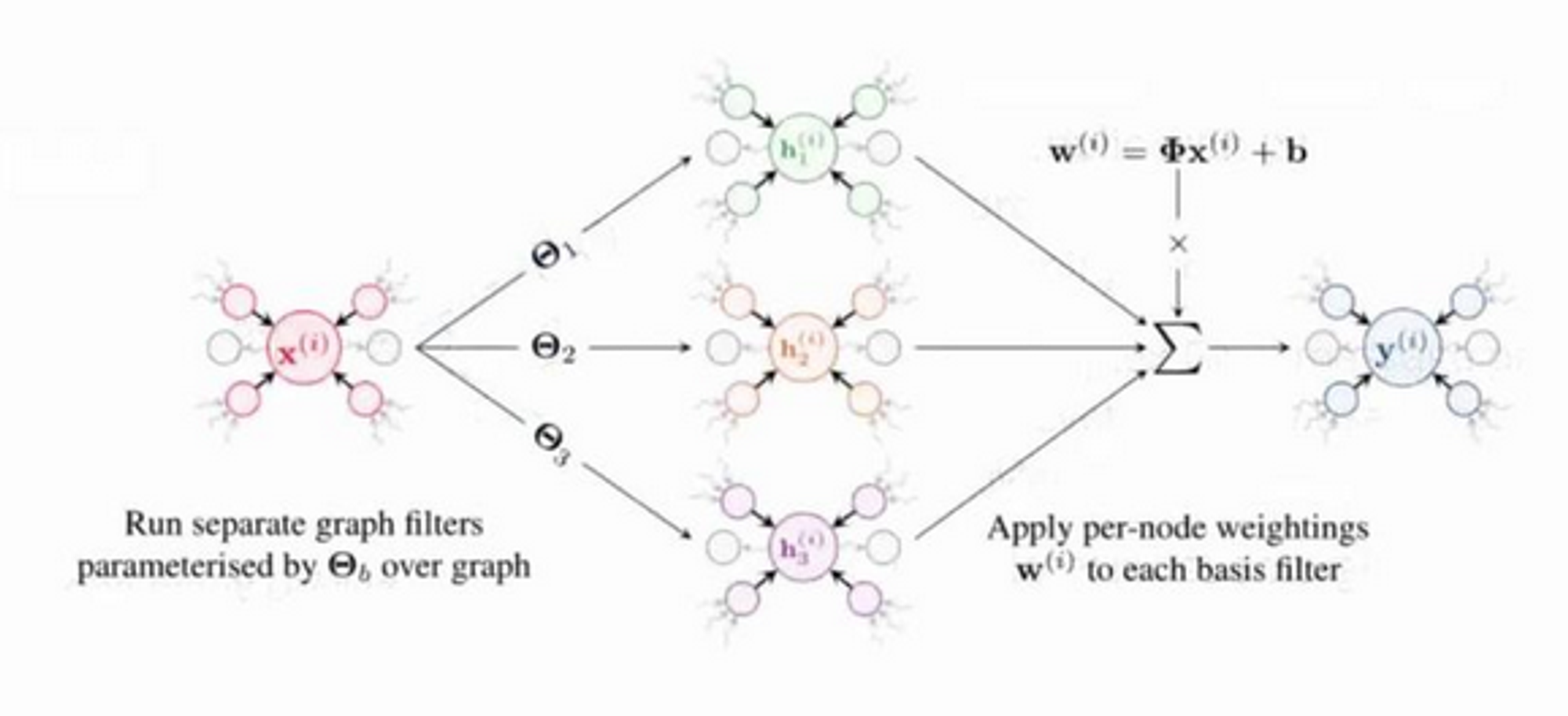
Key idea: anisotropic GNNs - treat neighbours differently
→ computational challenges:
- all edges must now be materialised
- compute becomes a lot less uniform - varies in different parts of the topology
- hardware challenges result - SpMM operations coming through only really support GCN-type models well. Poor support for "arbitrary message passing"

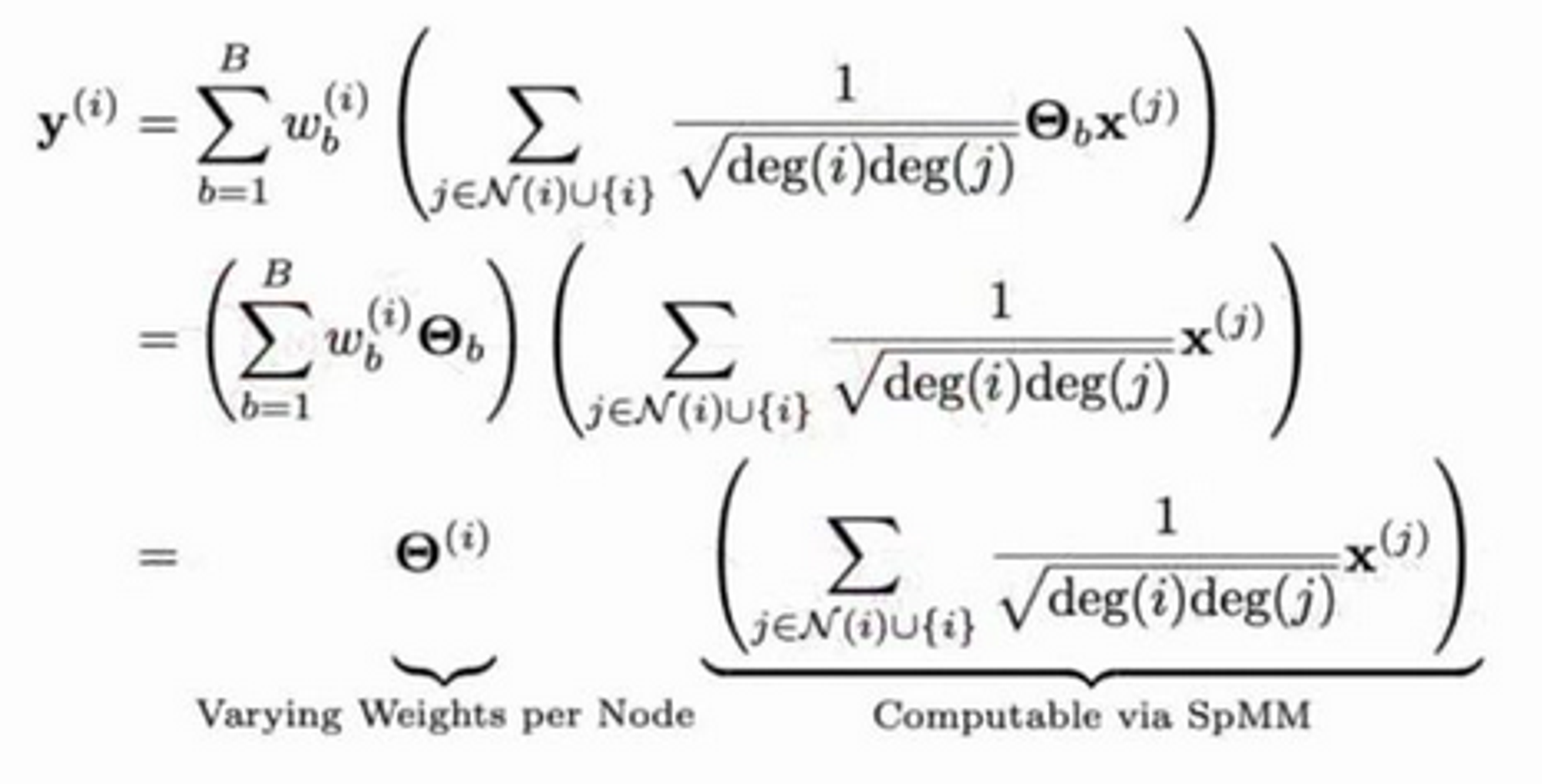
Method: The ECG Building Block