Introduction
For SIMD and also MIMD.
Some key differences between GPUs and CPUs:
- GPUs are accelerators (coprocessor?) that supplement a CPU - they don't need to be able to perform all of the CPU's tasks well, or even at all.
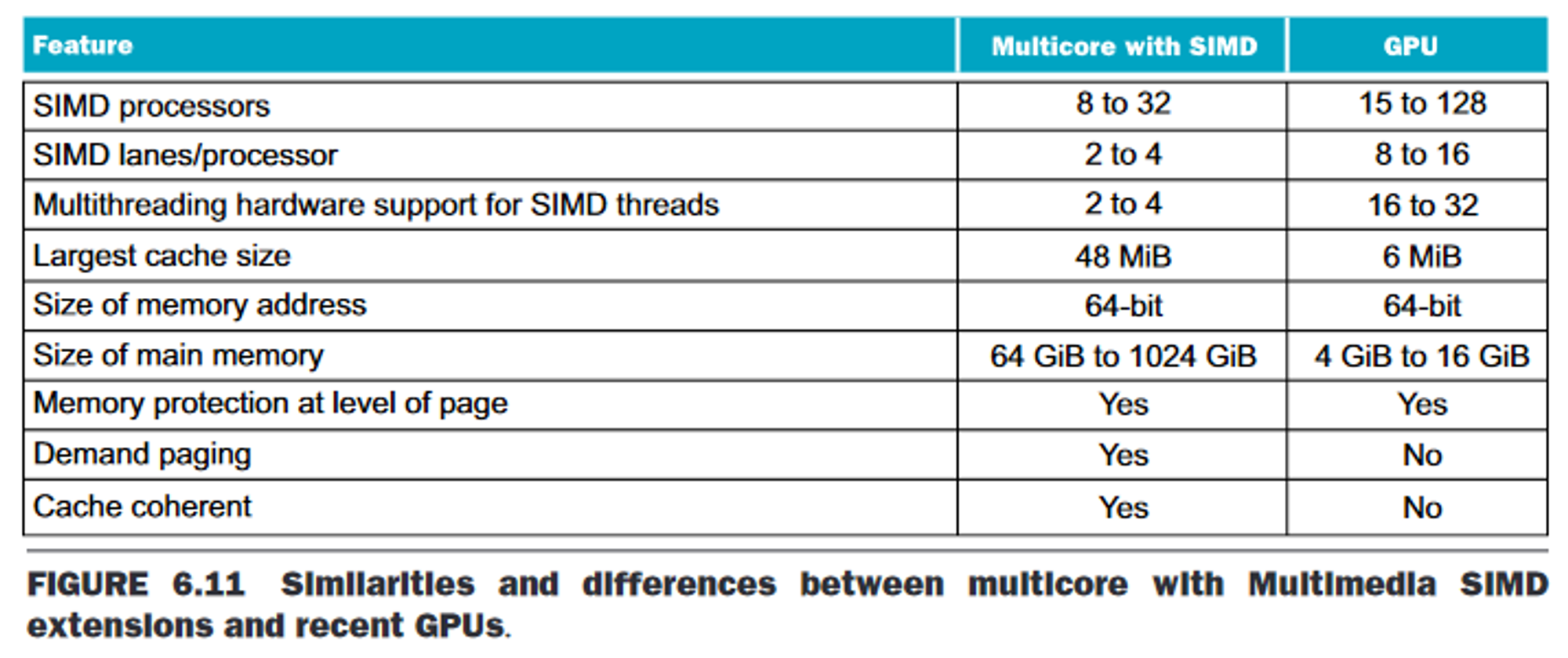
- GPU problem sizes are typically 100s of MB to GBs, but not 100s of GBs to TBs. In terms of on-chip memory, as of 2020, "GPUs typically have 4 to 16 GiB or less, whereas CPUs have 64 to 512 GiB or more".
- Do not rely on multilevel caches to overcome long latency to memory - instead rely on multithreading (switching between threads) to give time for mem access.
- (Thus) memory is oriented toward bandwidth over latency.
- Must also include time taken for transferring data between CPU and GPU memory, since CPU is still in charge.
- GPUs typically have many more parallel processors, and provide more threads.
Developed C-inspired languages to allow writing of programs directly to exploit GPU hardware: CUDA & OpenCL.
Case Study: NVIDIA Fermi Architecture
MIMD through multiple SIMD processors - this is what comprises a GPU:
a GPU contains a collection of multithreaded SIMD processors; that is, a GPU is a MIMD composed of multithreaded SIMD processors. For example, NVIDIA has four implementations of the Tesla at different price points with 15, 24, 56, or 80 multithreaded SIMD processors.
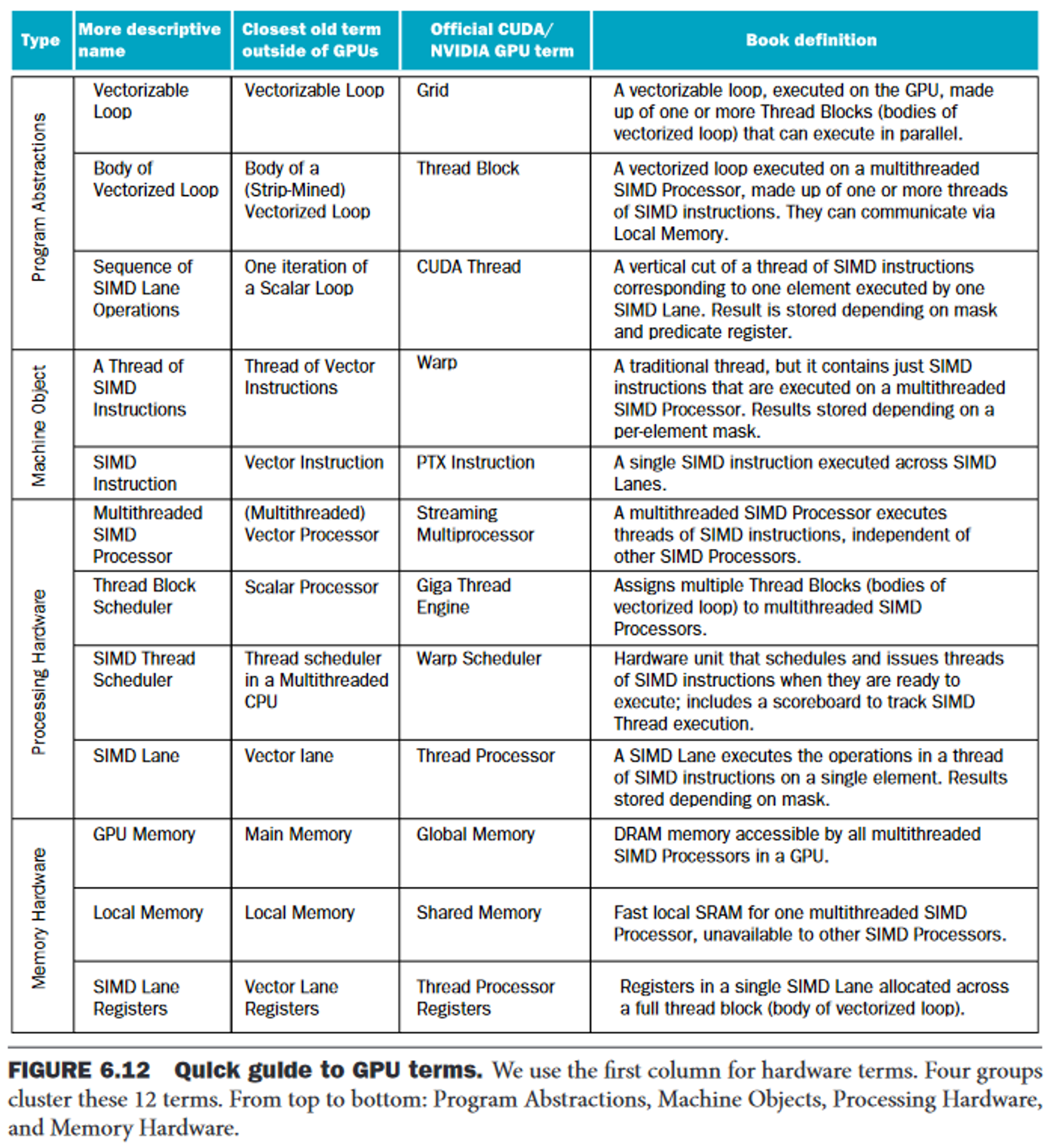
Traditional threads replaced by → what the authors call an SIMD thread:
- Like a normal thread but all instructions SIMD
- This becomes "the machine object that the hardware creates, manages, schedules, and executes"
Two levels of hardware schedulers:
- Thread Block Scheduler: assigns blocks of threads to multithreaded SIMD processors, inside which is...
- The SIMD Thread Scheduler.
Within an SMID processor there are parallel functional units to perform the operation - we call these SIMD Lanes.
Overview
of internal hierarchiy of GPU (multiple at lower layer for each higher-layer):
- (MIMD) GPU: Thread blocks & scheduler
- SIMD processor: SIMD threads (individual blocks, sz: 32 elements) & scheduler
- SIMD Lane: CUDA threads; a single functional unit
In terms of numbers, for 1 GPU we may have 15-80 SIMD processors, each with 16 SIMD lanes.
Note: A "kernel" is the process that is launched to invoke the GPU, which is broken down into the thread blocks.
Registers
Each SMID thread (32 elems) is mapped to 16 SIMD lanes so each instruction takes 2 clock cycles to complete. Threads executed in lock-step.
SMID processor has 32-bit registers, divided across 16 SIMD lanes - that is 2048 registers each.
Memory
Each SIMD processor has on-chip Local Memory, shared by lanes but not between SIMD processors.
The off-chip DRAM shared by the whole GPU (separete from CPU mem) is the GPU Memory.
Traditionally use smaller streaming caches and hide latency to DRAM using multithreading (many threads at once while loading).
More recent GPU have added caches.
Comparison
NVIDIA/GPU Terminology
TPUv1

- Matrix Multiply Unit (MXU): array of 256 x 256 ALUs → 25x as many as contemporary GPU (250x CPU)
- Using SIMD parallelism for all (simple!)
- From 32FP to 8/16Int
- Domain-specific Acc, Act, Pool
- Unified buffer of 24 MiB: 4x than GPU local mem
- Uses less power than alternative chips
- Key metric: 29 times the performance per watt of contemporary GPUs and 83 times the performance per watt of contemporary CPUs
Resources on the web
In-depth article about using GPUs for DL: here
Benchmarks: overview of current state, and about the benchmarks