Speaker: George Karypis
Recent work has shown applicability of GNNs to number of areas - now in phase of moving from research into industry.
DistDGL: Distributed GNN training in DGL
Challenges of distributed communication overhead
- Accessing non-local edges during sampling / mini-batch creation
- Accessing node/edge features
- Exchanging gradients
Challenges of computational load
- Depends on the size of the subgraphs corresponding to a device's current mini-batch
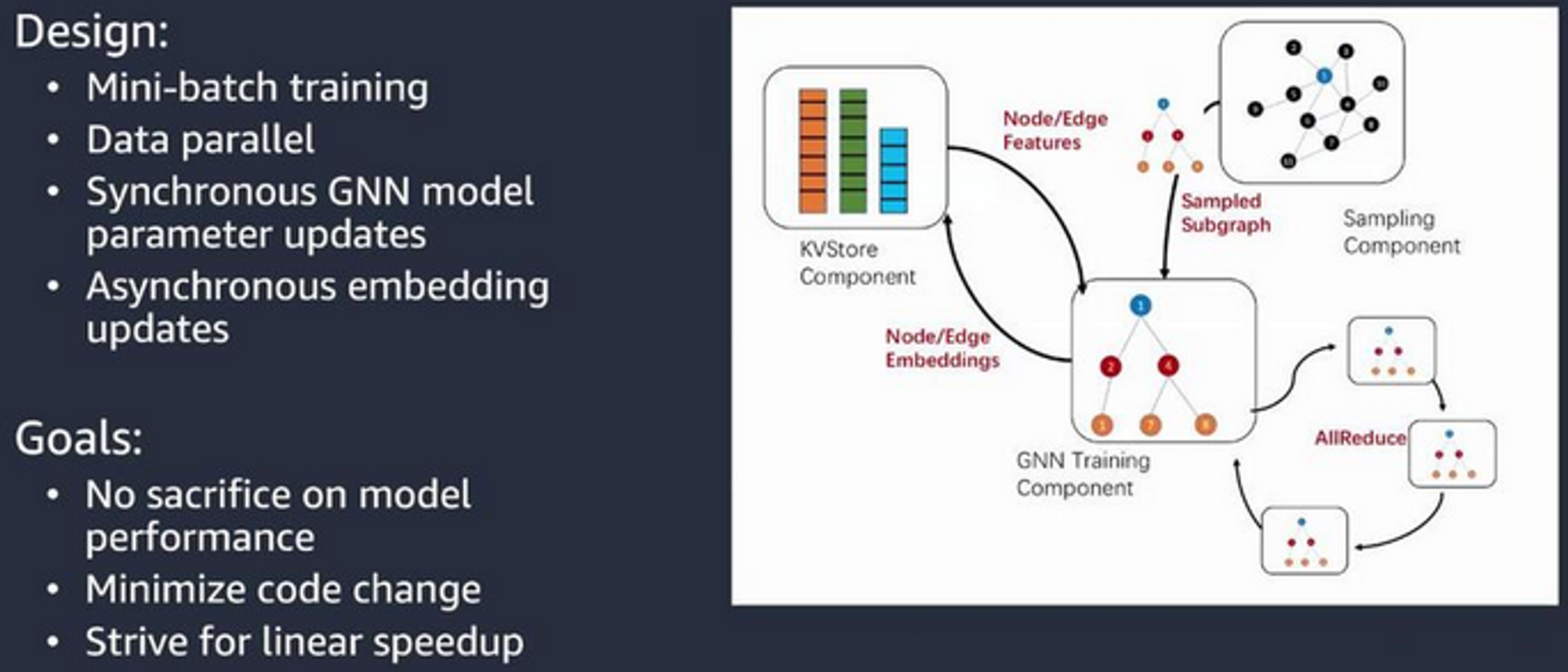
Distributed architecture
Partitions graph and assignes 1-1 partitions to machines.
Each machine is responsible for the operations involving its partition - each runs trainers, sampler servers and KVStore serveers.
Communication within a machine relies on shared data.
Scalability
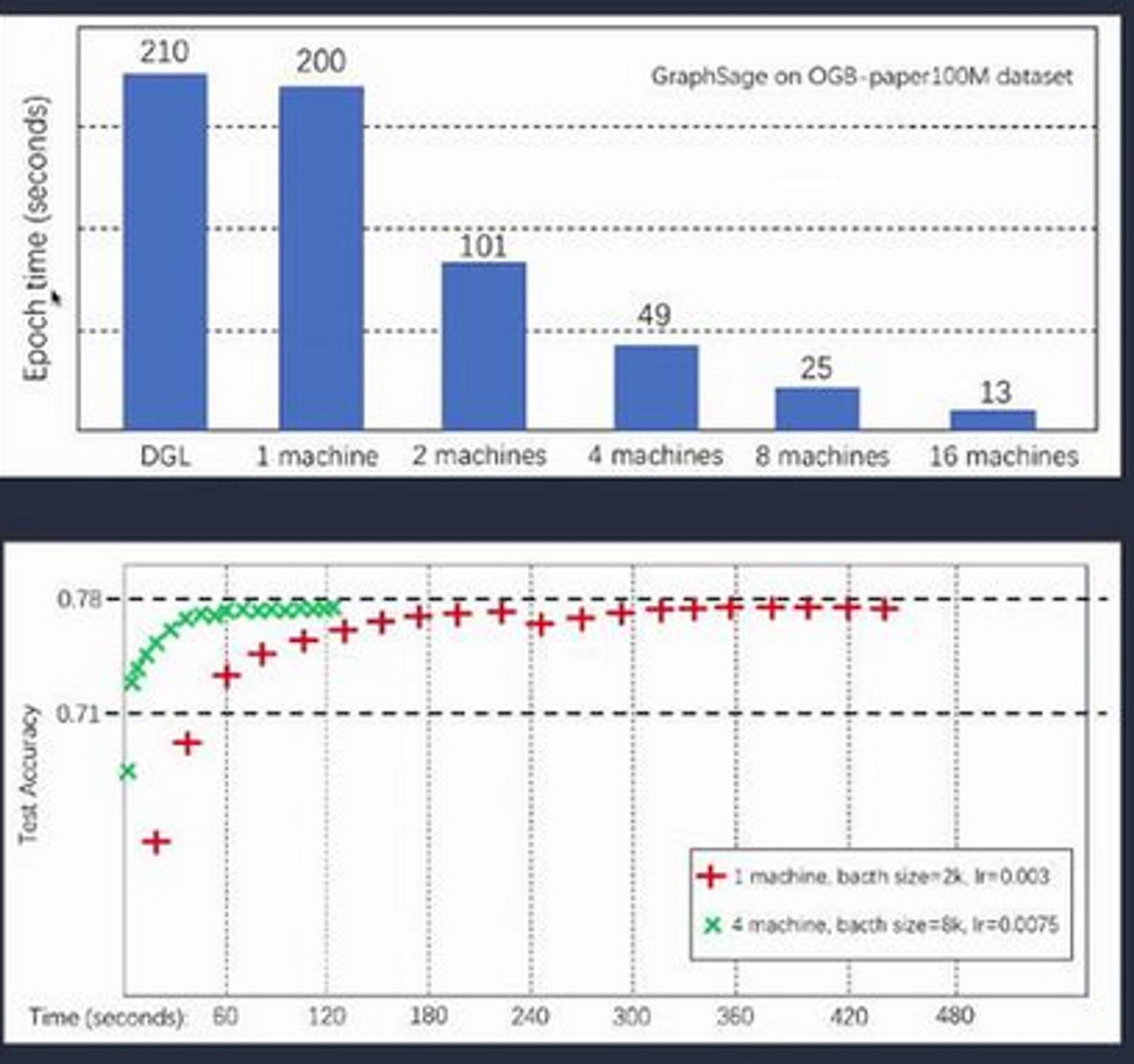
❗can scale to a graph with 110M nodes, 3.2B edges.
➡️ near-linear speedup with no compromise in model accuracy
Just CPUs here, but similar speedup for scaling GPUs.
Note also that 1 GPU outperforms 64 CPU cores.
2.4x better than Euler on a CPU cluster. Data copy speed: about 6x speedup, due to partitioning approach.
Key Challenge: balancing the computations
To address this, developed adaptive load balancing to improve performance (some batches more costly than others)
Also want to move more operations to GPU:
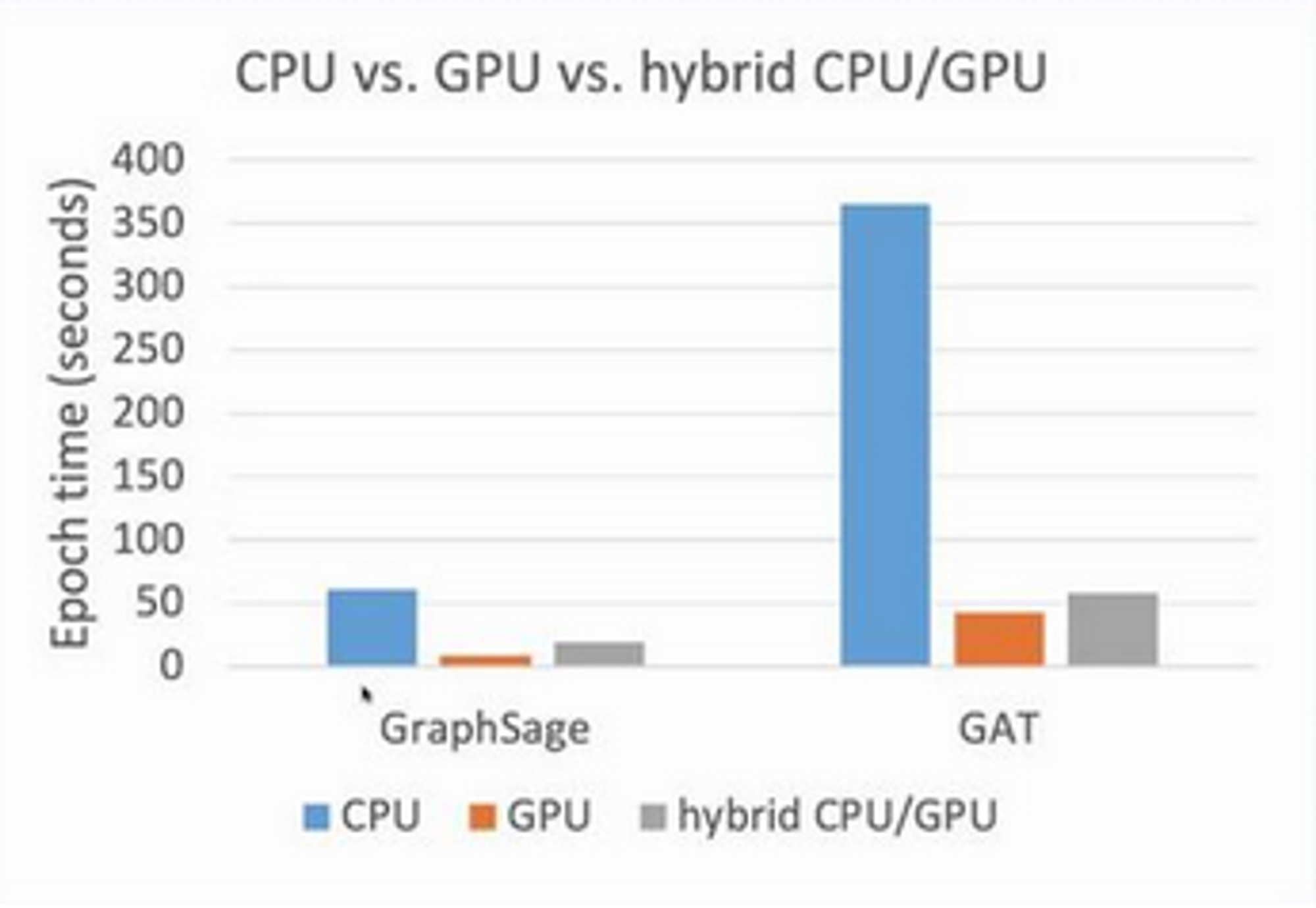
Aim: to move DGL to entirely-GPU based.
Amazon Neptune ML
Observation: Getting GNNs from training to production is hard
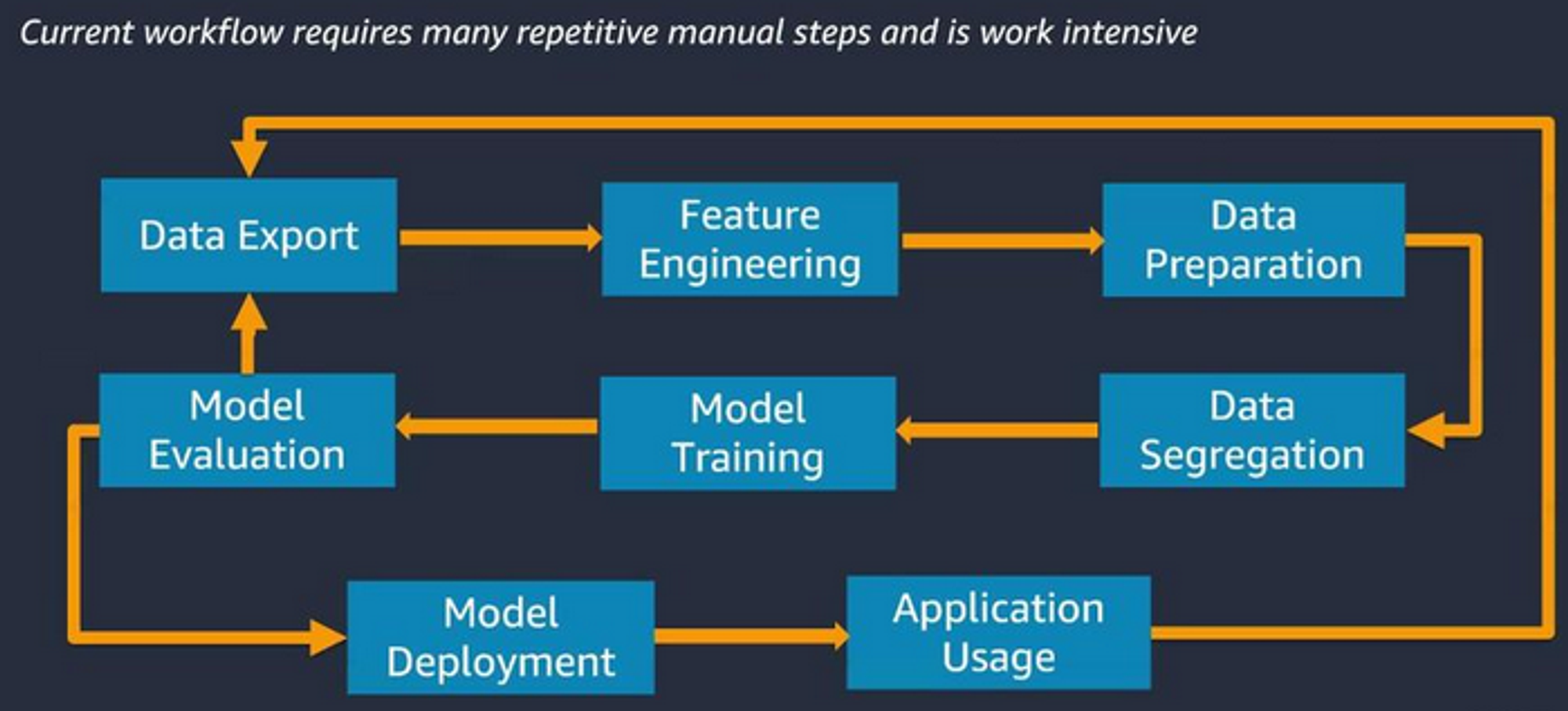
Solution: Amazon Neptune ML
Can be used to solve node/link classification/regression.
Supports inference during traversal
Inferrence can be done using gremlin query language.
Imagine an existing graph with some connected nodes. We then learn some links using a GNN. We can then use query language to optinally search the existing graph with an added endpoint for the trained model that gives us the new links for querying over too. We can query just the new links, to e.g. get movie predictions. 🔻

Development challenges
- Hyperparameter search / prioritisation
- Scaling linearly with number of GPUs on a single instance → PyTorch sparse embedding does not scale very well on multiple GPUs, so custom DGL sparse
NodeEmbeddingmodule used.
- Optimising link-prediction inference latency