MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers
Enormous language models lead to breakthroughs and new tasks, such as open-ended text-gen.
Open-ended text-generation task
Open-ended text-gen (OETG) has a problem: how to choose between equally valid alternatives?
Current solution: human evaluation ➡️ expensive & unreliable

Type 1 is the obvious error, but Type 2 also v important.
KL & reverse KL respectively are natural metrics for these
However, they can also be infinite ⚠️
Mauve Method
Solution: calculate KL with target as weighted mixture of Q & P. This gives the divergence curve.

The area under this curve is Mauve.
If MAUVE = 1 → P & Q are identical; 0 → completely dissimilar
Computing Mauve in practice
We require probabilities of the human documents we compare to. This is generally intractable. The solution has two steps:

So the deep embedding gives a continuous probability distribution (in embedding space). However, this is still quite high-dim to evaluate a probability distribution over. The quantisation method reduces this, making it tractable.
Note that interpretation of actual Mauve score is dependent on the embedding model (e.g. RoBERTa, or GPT2), but the comparison between scores (i.e. rank these three models) tend to be similar across embeddings.
Evaluation
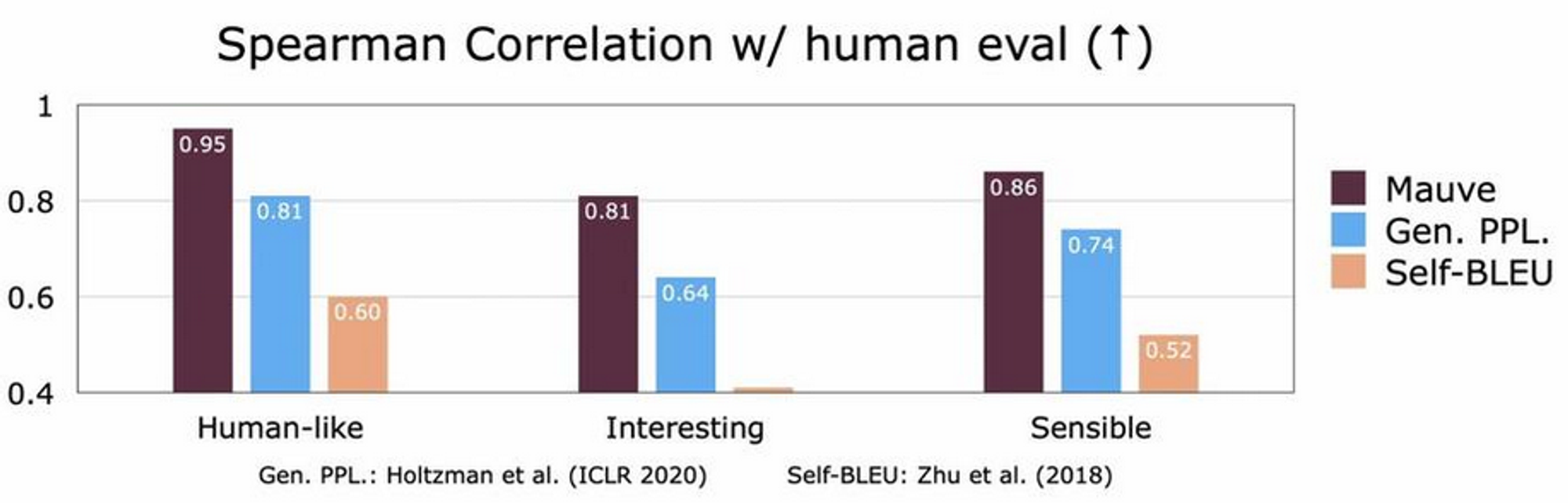
MAUVE correlates strongly with human judgements
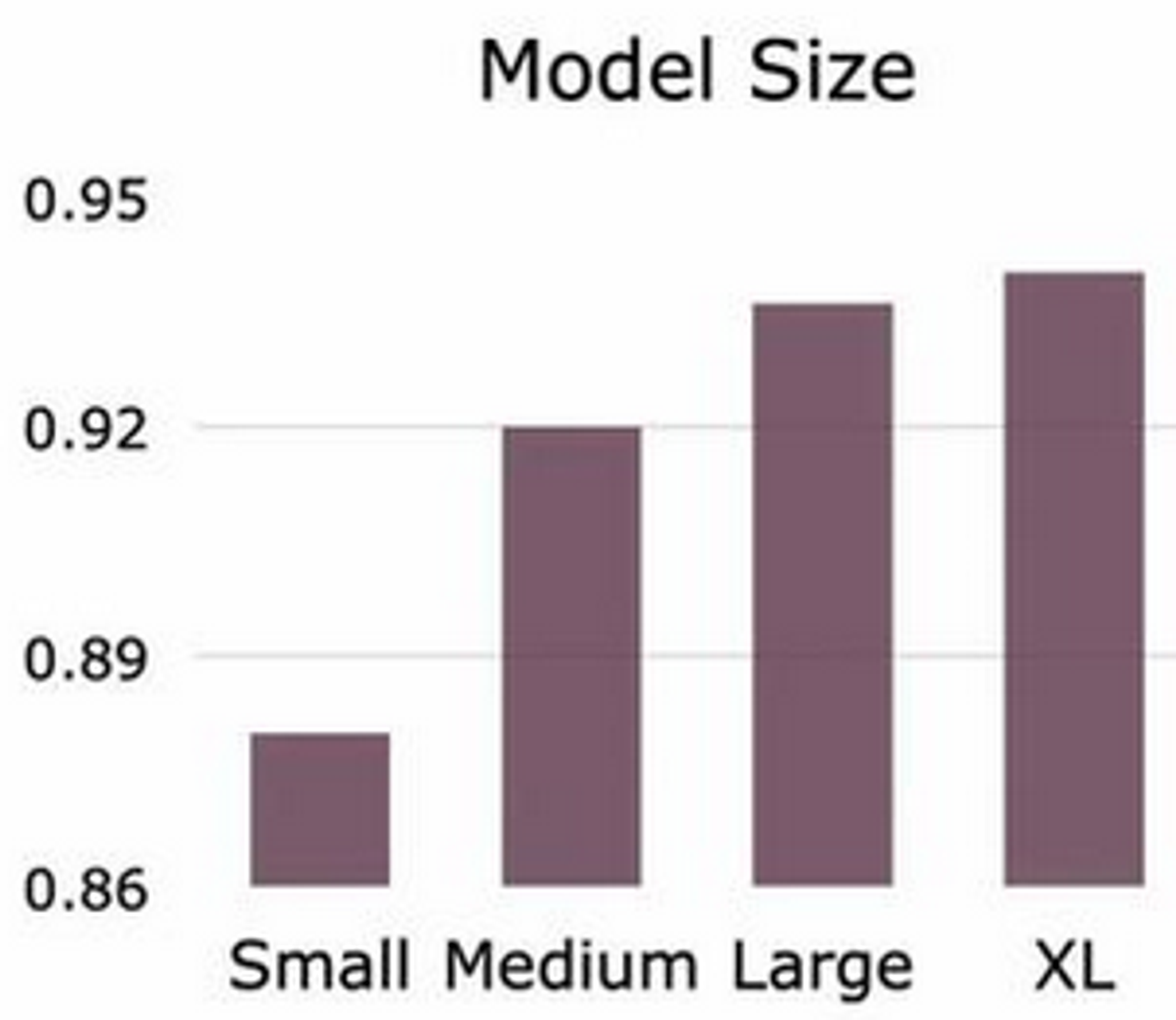
Also correlates with improvements coming from e.g. model size
That's it! Super simple. Why hasn't anyone thought of this before??
Questions
- What is nucleus sampling?
- How exactly do we get these distributions? How can both GPT2 and RoBERTa be used?