Sutton frames RL as "the whole AI problem in microcosm" - but is it?


Question: For any choice of task, can Markov reward always capture the chosen task?
Answer: no!
What is a task?
If it's anything that can be expressed by just reward, then obviously reward suffices.
But is there more to it?
What if a task is something that a reward is trying to capture, such as preferences?

Three potential definitions
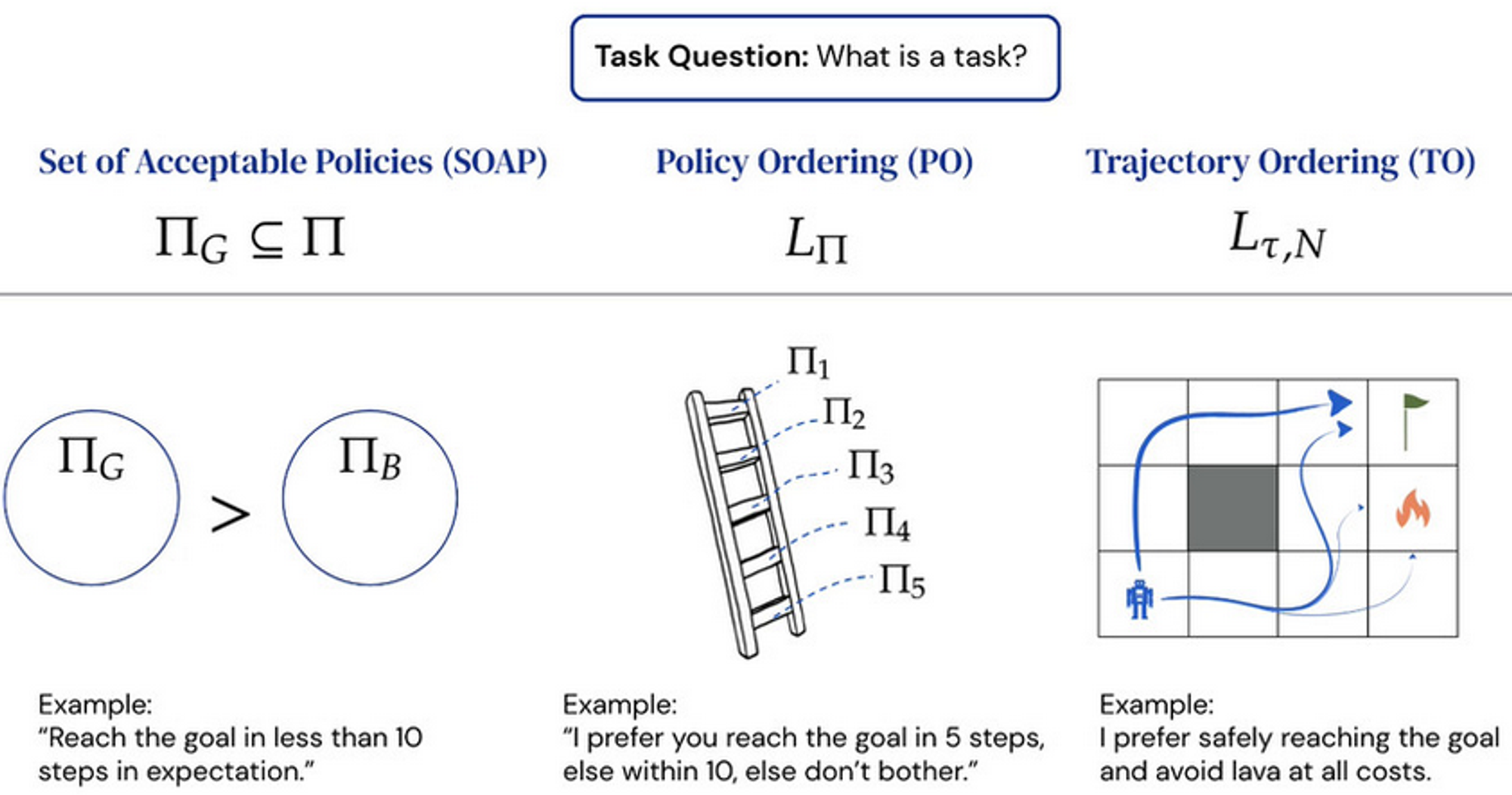
Can reward express these
Are these definitions of task all captured by reward?
Consider that each reward induces a value function for a policy in a given state, or a return for a trajectory.
Then for each of these task definitions we can capture the objective using a reward satisfying the following respective conditions:
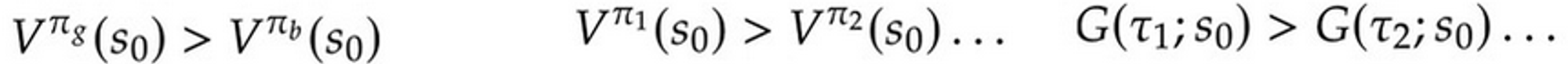
But does such a reward always exist? ⬇️
(Note that rewards always map to at most tuples)
Reward is not enough - for any of these definitions!

SOAPS that can't be expressed
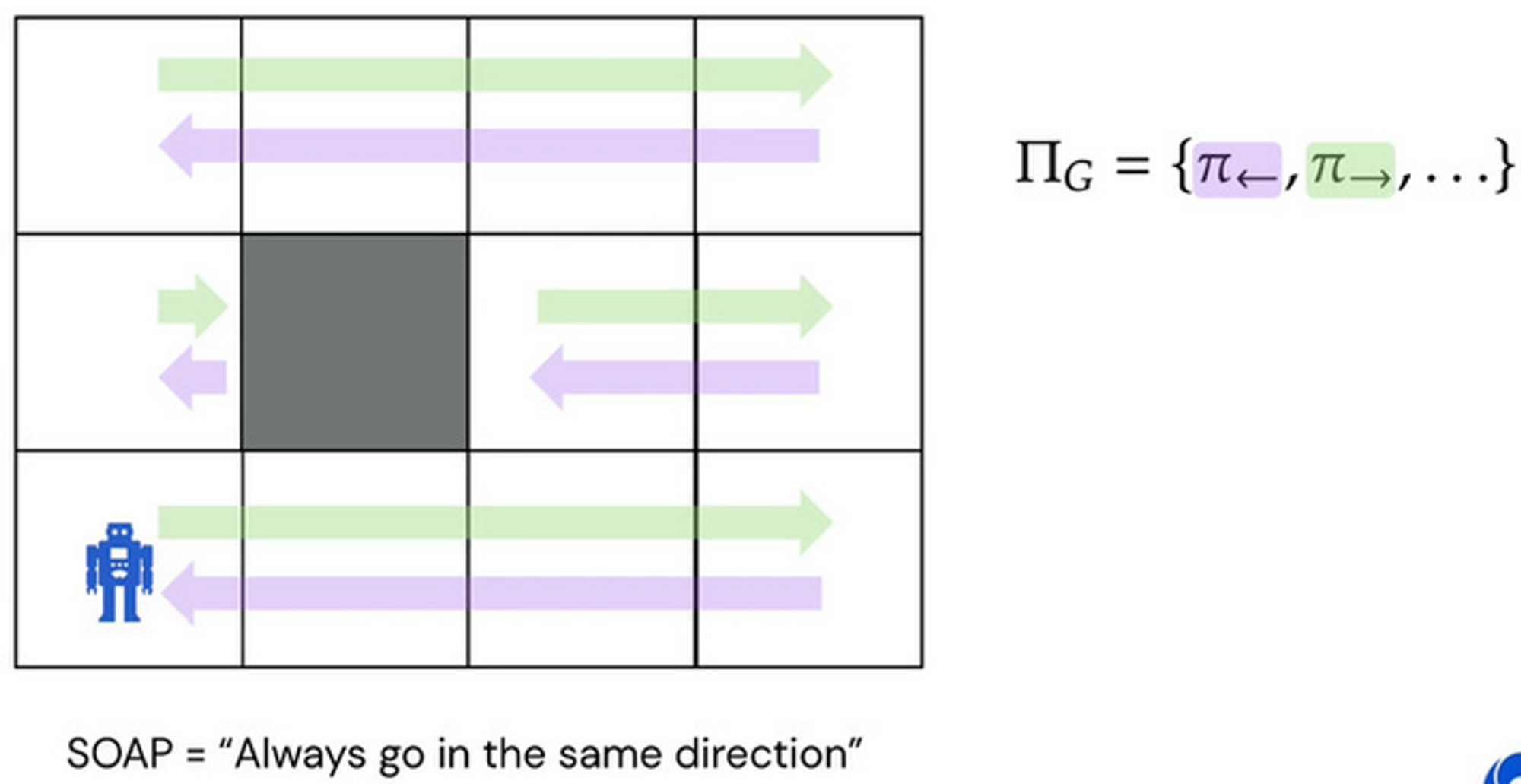
There is certainly a policy that can represent this (pictured), but no reward function induces this as the optimal policy.
Consider our requirement .
There can't exist a reward function that can make these policies strictly higher in start-state value than all other policies, as doing so would require knowledge of history.
Easier to see in simple example, where actions both do the same thing, but we are required to pick a policy which always flips its choice of action.
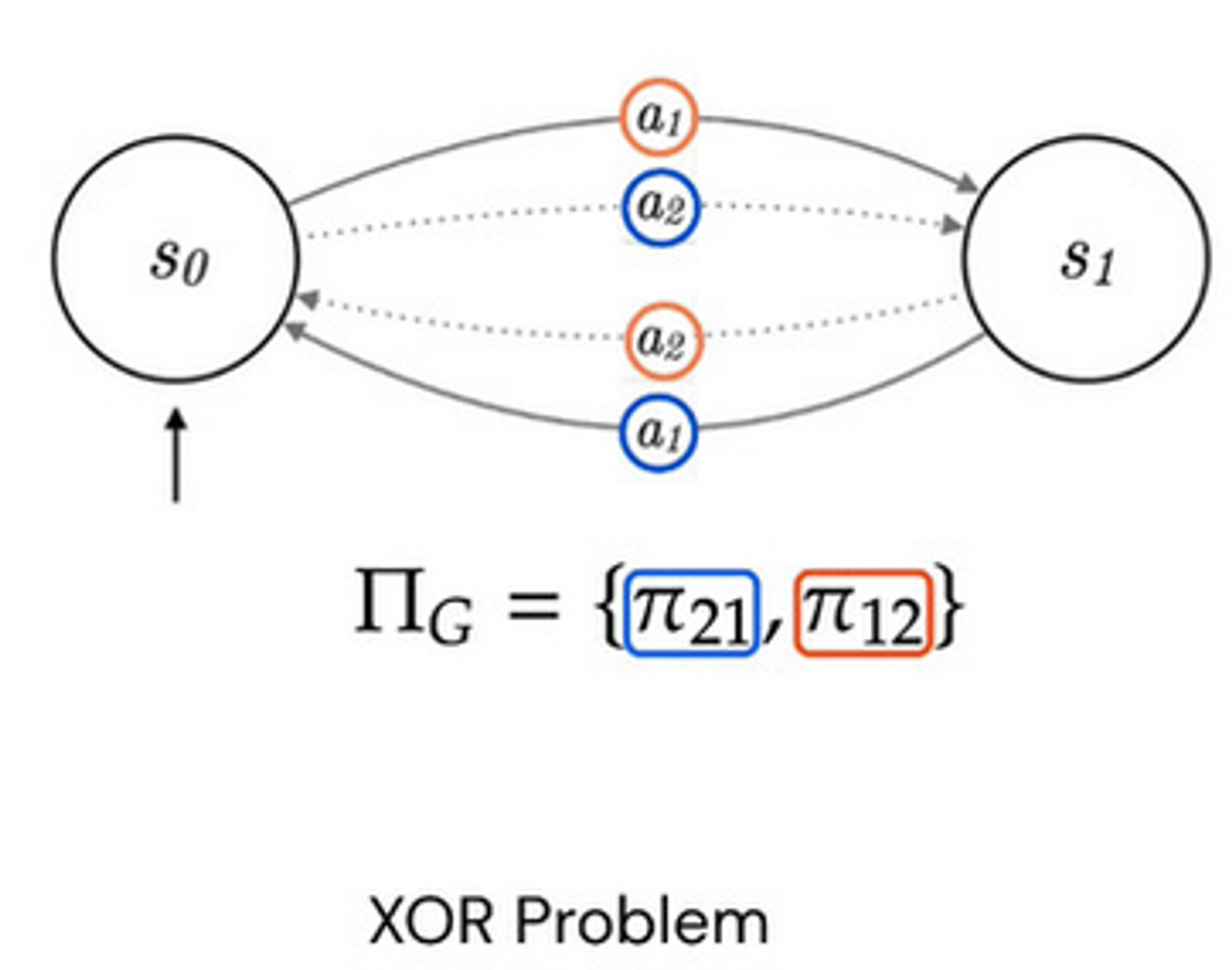
Clearly no reward based on tuples can express/incentivise/prioritise this, as the reward must condition on the previous action!
This suggests maybe the trajectory method (TO) is a better fit.
Generally, whenever the reward needed a tthe current timestep depends on history, SOAPs are not expressible.