In 5 bullet points
- Current models give increased performance when more parameters and data are used
- This leads to quadratic increase in training costs
- Using sparse gating with MoEs, we can train each param on the subset of the data it can help the most with
- This is done in a distributed way, within a layer of the network
- Allows models to be trained with far more parameters and still accrue expected performance gains, without huge increase in training costs
Overview
Context:
- Current limitation for ML is number of parameters
- With more parameters we also require more data
High-level problem: adding more parameters and more data to existing models gives a quadratic ⬆️ in training costs
High-level solution: MoE model where only parts of the model are active, conditional on the input
MoE problems addressed:
- Effective batch size can get so small as to be inefficient
- Network bandwidth can become a bottleneck
- Not been tried on large datasets
Method
Proposed approach:
Expert: ff-NN, 1 hidden layer + ReLU
Gate: softmax gating + noise + sparsity:
Rest: Word embedding layer, LSTM layers before & after
Experimental Details:
- Dropout
- Residual connections
- Activation checkpointing
- Attention mechanism between encoder and decoder
Distributed Implementation:
Data parallel: LSTM + gating layers
Model parallel: experts grouped across devices
Hierarchical MoE: first gating network = data-parallel, secondary MoEs = single device
Problems Solved
Small batch size:
Problem: As we add devices batch size shrinks
Solution: We can compute a group of sequential LSTM outputs and send them as a (macro)batch to the MoE layer ("convolutional approach")
Outcome: Increases effective batch size & efficiency
Network bandwidth:
Problem: Major limitation can be network bandwidth
Solution: Arithmetic intensity (ops:bytes) hidden layer size ()
Outcome: By using larger hidden layers we can hide cost of network
Expert importance balancing:
Problem: Vicious cycle where commonly selected experts trained more, get better, and are selected more
Solution: Add to loss
Outcome: Regularises gating mechanism to make experts equally important
Expert load balancing:
Problem: Importance loss equalises weights across batch, but not explicitly load
Solution: Add to loss
Outcome: Regularises gating mechanism to make experts equally important
Adam Adjustment:
Problem: Adam optimiser states take up too much memory
Solution:
- No first moment gradient estimates → just use current value
- Factored representation of each parameter matrix's second moment estimates
Experiments
1 Bn Word Language Modelling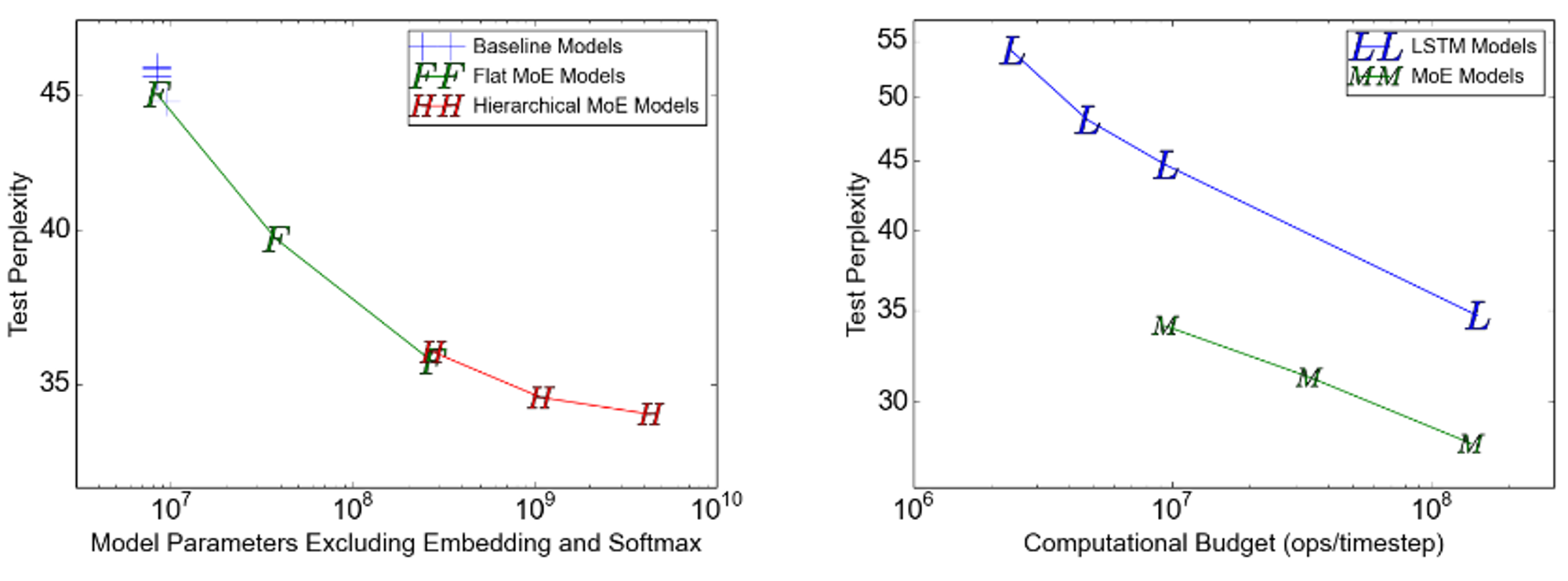
(Left) Fixed computational budget, increased no. experts; (Right) Fixed number of experts, increased budget.
Increased no. experts/params: Near-linear speedup for flat model; slight improvement beyond that for hierarchical.
Increased budget: Linear improvement, comparable to LSTM.
100 Bn Word Language Modelling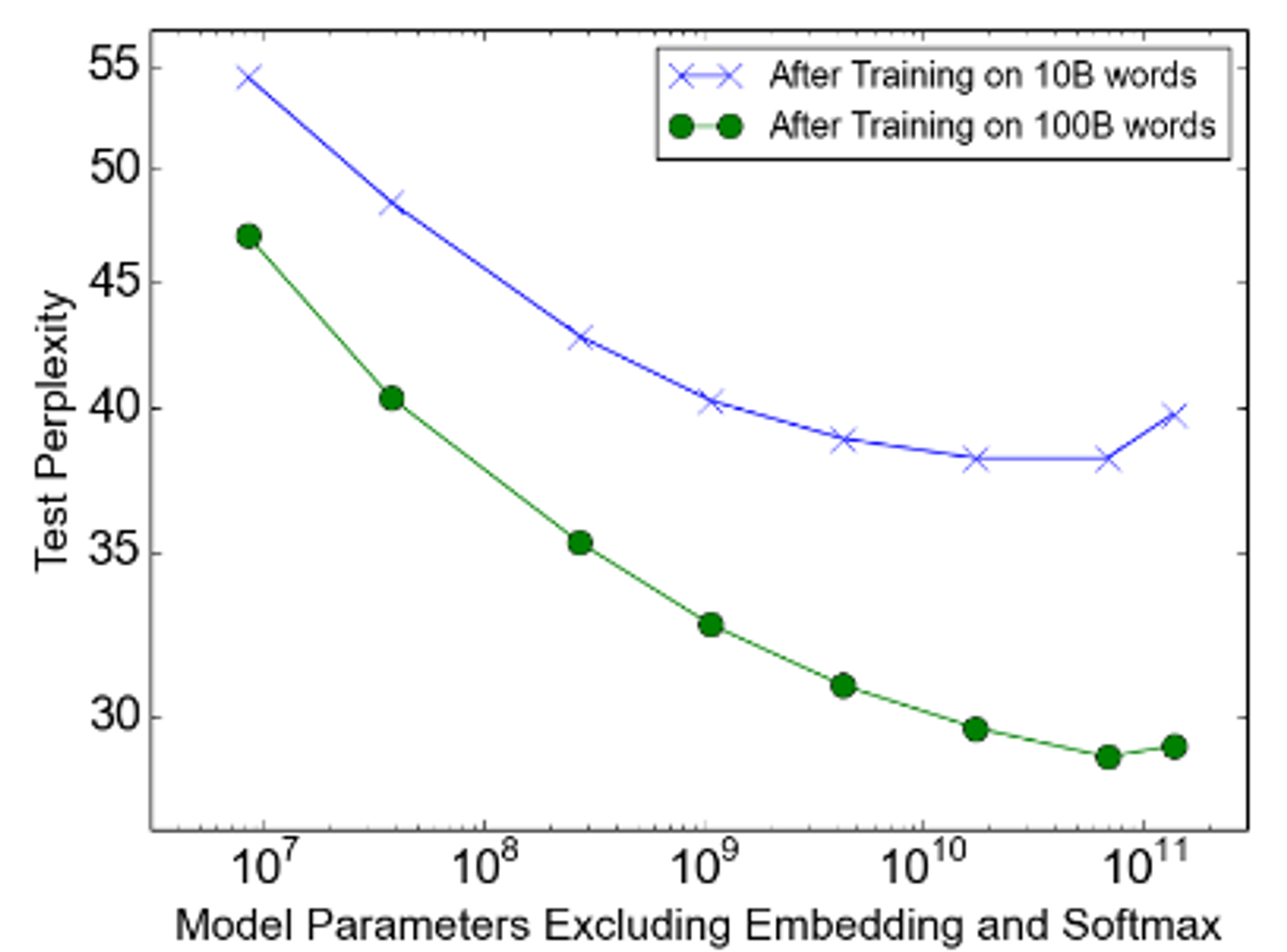
Increased no. experts/params: Linear speedup dropping off; can't quite scale to 100 bn params
Problem: Possible too much sparsity?
Increased data: Amount determines asymptote
Machine Translation: Far higher BLEU and lower perplexity than baselines, with far more params