Speakers: Bilge Acun, Chunxing Yin
Recommendation Models at FB:
- News Feed Ranking
- Stories Ranking
- Instagram Explore
In FB datacentres, they take up:
- ~50% of training
- ~80% of inference
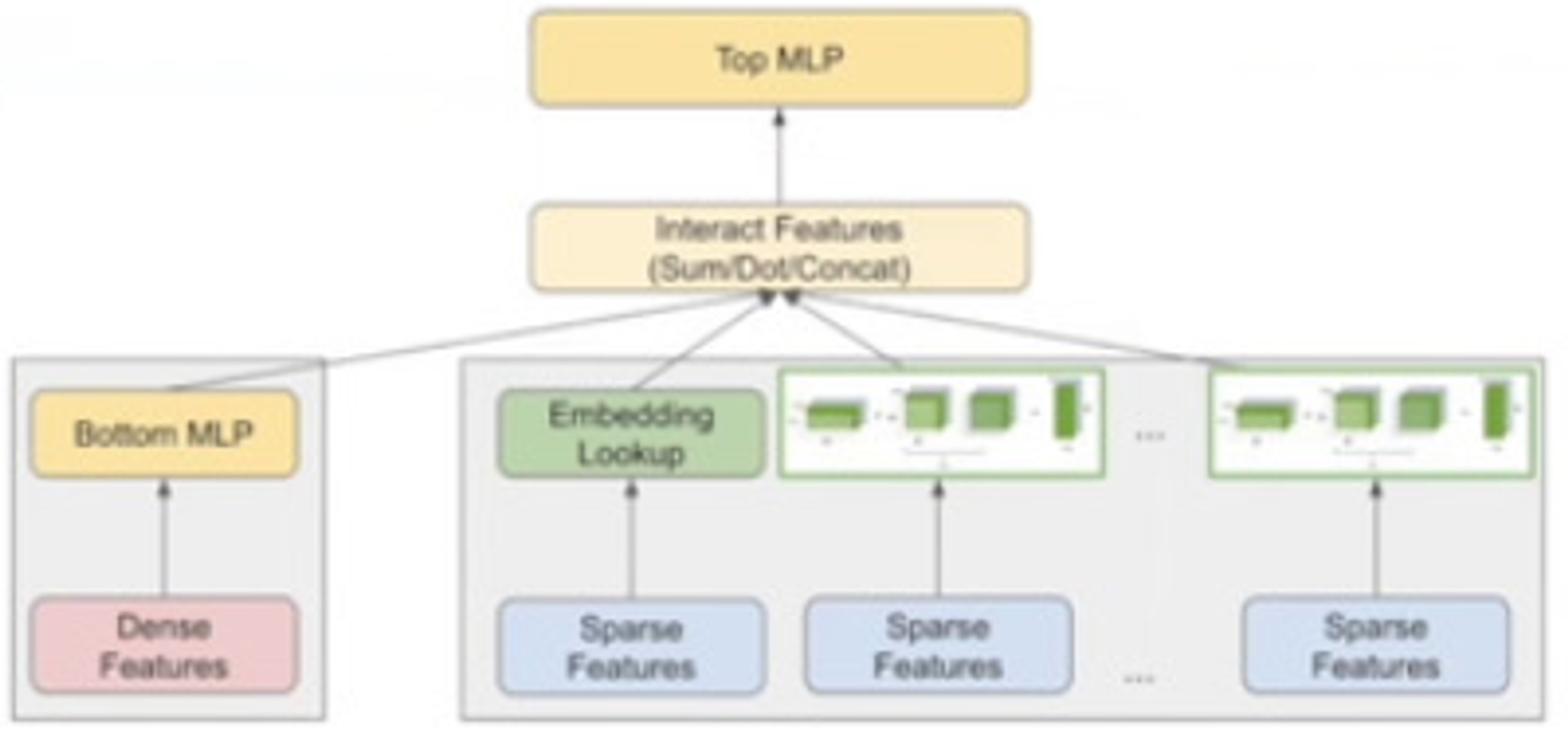
Deep Learning Recommendation Model (DLRM)

Includes sparse features: e.g. pages liked, videos watched, etc
Embedding lookup is a hashmap indexed by the sparse feature
From a systems perspective embedding learning is the most important part to optimise in these models.
Challenges in Embedding Learning
- Huge vocabulary size → mem capacity requirements of embedding tables have grown from 10s of GBs to TBs.
- Skewed data distribution in embedding tables → typically power-log distribution both for rows within a table, and the tables themselves
Motivation
AIM: "to make the tables smaller and denser, in order to trade off memory requirements for computation, to make them fit better to memory limited accelerators"

Tensor Train Compression
A low-rank tensor factorisation method
Tensor factorisation:

Think of the factorisation as an einsum, where each of the dimensions cancels out: the middle ones with each other, and the end ones with each other, as . This leaves the factorisation with the same dims as the original.
Application to DLRM
Replace emb with TT format, with appropriately chosen TT-rank.
TT-cores learned during training.
Challenges:
- Low-rank approximation performance degradation
- Hyperparameter tuning for TT-ranks
- Extra compute required
Benefit: Memory Reduction
- Compress the largest embeddings
- Overall model reduction ranges from 4x to 120x
Model quality
In some cases can actually improve accuracy
Comparison vs Hashed Embeddings
Hashed embeddings simply hashes multiple embeddings into one bucket to reduce size
Note: the two can be combined.
Both methods appear similar? Is this an improvement?